Warum eine Instandhaltungsstrategie heute über den ROI entscheidet
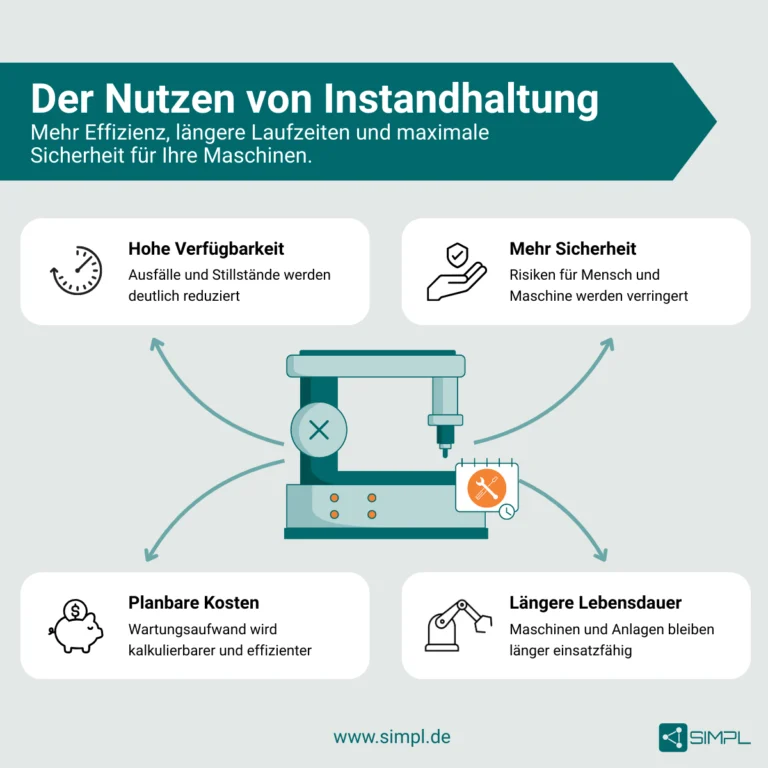
Ungeplante Stillstände kosten schnell vier- bis fünfstellige Beträge pro Stunde. Gleichzeitig steigen Anforderungen durch Automatisierung, Fachkräftemangel und striktere Qualitäts-/Sicherheitsvorgaben. Eine saubere Instandhaltungsstrategie…
-
reduziert ungeplante Stillstände und Ausschuss,
-
verlängert die Nutzungsdauer von Anlagen,
-
macht Kosten planbar (CAPEX ↔ OPEX),
-
hebt OEE (Verfügbarkeit × Leistung × Qualität),
-
schafft die Datenbasis für Digitalisierung (CMMS/EAM, IoT, Analytics).
Merksatz: Strategie = Regelwerk, wann, warum und wie gewartet wird – nicht nur wer schraubt.
Begriffe & Normbezug (kompakt)
-
Instandhaltung: Kombination aus technischen, administrativen und Management-Maßnahmen über den Lebenszyklus eines Assets (vgl. DIN EN 13306 – zentrale Referenz für Begriffe).
-
MTBF/MTTR: Mean Time Between Failures / Mean Time To Repair – Kernkennzahlen zur Verfügbarkeit.
-
OEE: Overall Equipment Effectiveness, Verfügbarkeitsanteil direkt von Instandhaltung beeinflusst.
-
CMMS/EAM: Software zur Planung, Durchführung, Dokumentation & KPI-Steuerung.
(Weitere relevante Rahmenwerke: ISO 55000/55001 Asset Management, branchenspezifische VDMA-/VDI-Blätter; je nach Branche gelten zusätzliche Vorgaben.)
1) Korrektive Instandhaltung (reaktiv / Run-to-Failure)
Die korrektive Instandhaltung folgt einem einfachen Prinzip: Es wird erst gehandelt, wenn ein Fehler auftritt. Diese Strategie hat ihre Berechtigung, wenn Ausfälle überschaubare Konsequenzen haben, Ersatzteile gut verfügbar sind oder Redundanzen vorhanden sind. Sie ist oft die kostengünstigste Herangehensweise in der Anschaffung (nahezu kein CAPEX), kann aber in der Summe teuer werden, wenn Stillstandskosten hoch sind oder Ausfälle Folgeschäden verursachen (z. B. Bauteilverzug, Ausschuss, Sicherheitsrisiken).
Wichtig ist, korrektive Wartung bewusst einzusetzen: Eine ABC-Klassifizierung der Assets hilft, unkritische C-Assets (z. B. Leuchtmittel, kleine Lüfter, Hilfsaggregate) korrektiv zu betreiben, während A-Assets (Engpassanlagen) abgesichert werden. Der Prozess lebt von schneller Störungsannahme, klaren Eskalationswegen und guter Ersatzteillogistik (Sicherheitsbestände, Lieferantenvereinbarungen). Ohne diese Grundlagen kippt korrektiv schnell in lange MTTR und hohe Opportunitätskosten.
Ein typischer Fehler ist die „versteckte Prävention“: Teams reagieren zwar korrektiv, investieren aber viel Zeit ins „Feuerlöschen“ (Ad-hoc-Inspektionen, unstrukturierte Checks) — mit schlechter Datenlage und ohne Lernkurve. Sinnvoller ist es, korrektiv als Teil einer Hybridstrategie einzusetzen (z. B. opportunistische Wartung während geplanter Stopps, Root-Cause-Analysen nach jeder größeren Störung).
Praxisbeispiel: Ein Verpackungsbetrieb betreibt Förderrollen korrektiv. Ausfälle führen zu kurzen Stopps, Techniker tauschen Rollen innerhalb von 15 Minuten (MTTR niedrig). Für die Engpass-Etikettierer gilt dagegen präventiv/CBM.
Auf einen Blick – Korrektiv
Vorteile
- Keine Vorabinvestitionen, einfache Organisation
- Maximale Nutzung der Bauteillebensdauer
- Sinnvoll bei geringen Ausfallfolgen
Nachteile
- Unplanbare Kosten & Stillstände (hohes Risiko)
- Gefahr von Folgeschäden und Sicherheitsrisiken
- Hohe Abhängigkeit von Ersatzteil- & Personalverfügbarkeit
Geeignet für
- Unkritische C-Assets, günstige/leicht austauschbare Teile
- Systeme mit Redundanzen oder geringer Qualitätswirkung
Nicht geeignet für
- Engpassanlagen, sicherheitskritische Funktionen, regulatorische Prüfpflichten
Daten & Tools
- Störungs-/MTTR-Erfassung im CMMS, Ersatzteil-ABC, Bereitschafts- & Eskalationsregeln
Typische Maßnahmen
- Notfallpläne, Standard-Wechselanleitungen, modulare Austauschbaugruppen
Kennzahlen
- MTTR, Anzahl Störungen, Verfügbarkeitsverlust durch ungeplante Stopps, First-Time-Fix-Rate
2) Vorbeugende Instandhaltung (präventiv / zeit- oder nutzungsbasiert)
Die vorbeugende Instandhaltung ersetzt Teile oder führt Inspektionen nach festen Intervallen (Zeit, Betriebsstunden, Zyklen) durch. Sie ist die Standardstrategie in vielen Werken, weil sie Planbarkeit schafft: Ressourcen, Ersatzteile und Stillstände können im Voraus eingeplant werden. Das reduziert Überraschungen und stabilisiert die OEE—vor allem, wenn Verschleiß und Alterung vorhersagbar sind (z. B. Riemen, Filter, Lager mit definierten Standzeiten).
Die Herausforderung liegt im optimalen Intervall. Zu kurze Intervalle führen zu Overmaintenance (Kosten steigen, ohne Ausfälle wirklich zu senken). Zu lange Intervalle lassen das Ausfallrisiko steigen. Gute Praxis ist ein Lebenszyklus-Review pro Bauteil: Start mit Herstellerempfehlungen, dann Anpassen anhand der eigenen Störhistorie (Weibull-Analysen, Trendbeobachtung). Präventive Programme funktionieren nur mit sauberer Arbeitsvorbereitung (Arbeitspläne, Checklisten, Materialreservierungen) und hoher Schedule Compliance in der Ausführung.
Präventive Wartung lässt sich effektiv mit opportunistischer Wartung kombinieren (Bündeln von Aufgaben bei geplanten Stopps), um Stillstandzeiten zu minimieren. Für A-Assets ist oft ein Mix aus Prävention + CBM sinnvoll: Standardwechsel plus gezielte Zustandschecks, die Intervalle dynamisieren.
Praxisbeispiel: Eine Pumpenstation wird alle 4.000 Betriebsstunden präventiv gewartet. Nach Auswertung der Störhistorie wird das Intervall auf 3.500 h für bestimmte Lager gesenkt, während Filterwechsel dank Ölzustandsprüfung verlängert werden.
Auf einen Blick – Präventiv
-
Vorteile
-
Hohe Planbarkeit (Personal, Teile, Downtime)
-
Verlängerte Lebensdauer, weniger ungeplante Ausfälle
-
Einfache Einführung, Herstellerempfehlungen verfügbar
-
-
Nachteile
-
Risiko der Überwartung (unnötige Kosten)
-
Bindet Ressourcen/Teile, wenn Intervalle zu konservativ sind
-
Findet nicht jeden Zufallsfehler
-
-
Geeignet für
-
Verschleißdominiert, normierte Inspektionspflichten, Standardaggregate
-
-
Nicht geeignet für
-
Ausfallmuster ohne klare Alterung, schwer planbare Anlagenzustände
-
-
Daten & Tools
-
CMMS mit Intervall-Logik (Zeit/Betriebsstunden), Checklisten, Teile-Disposition
-
-
Typische Maßnahmen
-
Intervall-Matrix je Asset, Bündelung (opportunistisch), kontinuierliches Intervall-Tuning
-
-
Kennzahlen
-
Planned Maintenance Percentage (PMP), Schedule Compliance, Wiederholfehlerrate, Kosten pro präventivem Auftrag
-
3) Zustandsbasierte Instandhaltung (CBM – Condition-Based Maintenance)
Bei CBM wird nur gewartet, wenn der tatsächliche Zustand es erfordert. Grundlage sind Messwerte und Grenzwerte, die eine Abweichung vom Normalzustand anzeigen: Vibrationen, Temperatur, Stromaufnahme, Durchfluss, Ölpartikel, Ultraschall etc. CBM ist ein starker Effizienzhebel, weil es präventive Pauschalwechsel reduziert und ungeplante Ausfälle früh erkennt. Es erfordert jedoch Sensorik/Prüfroutinen, definierte Alarmstufen (Info/Warning/Critical) und klare Workflows: Wer bewertet? Welche Maßnahme wird bei welchem Schwellenwert ausgelöst?
Der größte Erfolgsfaktor ist die Signalqualität: Falsch montierte Sensoren, fehlende Referenzmessungen oder „Alarmfluten“ aus schlecht gesetzten Grenzwerten untergraben die Akzeptanz. Ebenso wichtig: Kontextdaten (Drehzahl, Last, Temperatur), damit Zustandsindikatoren richtig interpretiert werden. In der Einführungsphase empfiehlt sich ein Pilot auf 1–3 kritischen Baugruppen, um Messkonzepte und Grenzwerte zu schärfen und den Business Case zu beweisen.
CBM lässt sich hervorragend mit präventiver Wartung koppeln: Standard-Checks bleiben, zustandskritische Komponenten werden bedarfsorientiert behandelt. So entstehen dynamische Intervalle, die Kosten senken und die Verfügbarkeit erhöhen.
Praxisbeispiel: An kritischen Motorlagern werden Beschleunigungs- und Hüllkurvenwerte erfasst. Bei Anstieg der Schwingung in Bandpass X wird ein Inspektionsauftrag generiert; bei Überschreiten von Grenzwert Y wird ein kontrollierter Tausch im nächsten Rüststopp eingeplant.
Auf einen Blick – Zustandsbasiert (CBM)
-
Vorteile
-
Weniger unnötige Eingriffe, höhere Verfügbarkeit
-
Früherkennung von Fehlern (gezielte Eingriffe, kürzere MTTR)
-
Dynamische Intervalle, bessere Teile-/Personaldisposition
-
-
Nachteile
-
Sensorik/Prüfroutinen und Know-how nötig
-
Pflege von Grenzwerten/Alarmierung (Gefahr der Alarmmüdigkeit)
-
Aufwand für Dateninterpretation & Prozessintegration
-
-
Geeignet für
-
Kritische Baugruppen mit aussagekräftigen Zustandsindikatoren (Lager, Spindeln, Förderketten)
-
-
Nicht geeignet für
-
Komponenten ohne messbaren Vorläufer (reine Zufallsfehler) oder ohne wirtschaftlichen Messaufwand
-
-
Daten & Tools
-
Sensoren/Portable Messgeräte, Edge/Gateway, Visualisierung, CMMS-Workflows, Messstellenkatalog
-
-
Typische Maßnahmen
-
Referenzmessungen, Alarmstufen, Diagnoseleitfäden, Schulungen (Messtechnik/Interpretation)
-
-
Kennzahlen
-
Anteil zustandsbasierter Aufträge, Reduktion ungeplanter Stopps, Alarm>Auftrag-Konversionsrate, Falsch-Alarm-Quote
-

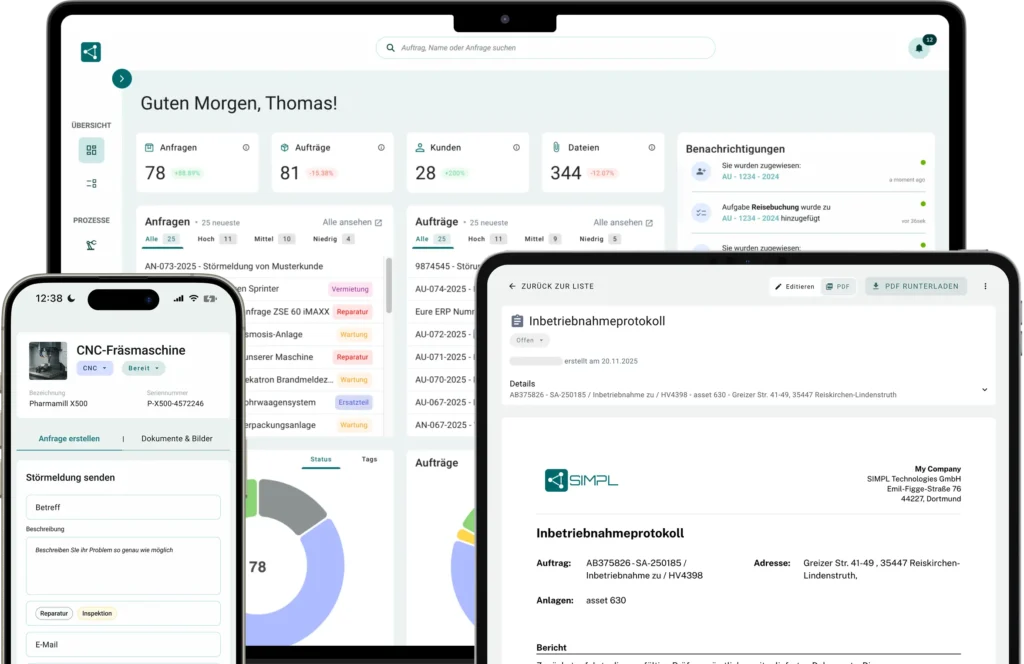
Setze deine Instandhaltungsstrategie digital um.
Erfahre, wie du Wartungen, Anlagen & Aufgaben zentral planst und dokumentierst.
4) Vorausschauende Instandhaltung (Predictive Maintenance, PdM)
Predictive Maintenance geht über CBM hinaus: Aus historischen und Live-Daten werden mittels Statistik/ML Ausfallwahrscheinlichkeiten und Restlebensdauern geschätzt. Ziel ist, den optimalen Eingriffszeitpunkt zu bestimmen — so spät wie möglich, so früh wie nötig. PdM zahlt sich vor allem bei sehr kritischen, teuren Assets aus, bei denen ungeplante Ausfälle einen hohen wirtschaftlichen Schaden verursachen.
Die Hürden liegen weniger in Algorithmen als in Datenzugang, Qualität und Prozessreife: konsistente Stammdaten, saubere Ereigniscodes, ausreichend positiv/negativ gelabelte Störfälle, stabile IT/OT-Integration. Ein erfolgreicher PdM-Start ist in der Regel Use-Case-getrieben: 1–2 Engpassanlagen, klarer KPI-Zielwert (z. B. –30 % ungeplante Downtime), definiertes Mess-Setup, begleitende Change-Maßnahmen (Vertrauen in Modell-Outputs, klare Verantwortlichkeiten). PdM ersetzt nicht die Basisarbeit — ohne CMMS-Disziplin, standardisierte Wartungspläne und saubere Messkonzepte bleiben Effekte aus.
Technisch gibt es zwei typische Ansätze: Modelle je Komponente (z. B. Lager-RUL auf Basis Schwingungsfeatures) oder linienweite Anomalieerkennung (Multisignal, Prozess-/Qualitätsdaten inkl.). Wichtig sind Erklärbarkeit (Warum Alarm?) und Handlungsanweisungen (welcher Auftrag wird erzeugt?). Der Wert entsteht erst, wenn Prognosen zuverlässig zu geplanten Maßnahmen werden.
Praxisbeispiel: Auf einer Abfülllinie korreliert der Anstieg eines kombinierten Health-Index (Vibration + Stromaufnahme + Temperatur) mit Spindellagerschäden ~7–14 Tage vor Ausfall. Ein ML-Modell gibt „Maintenance Window in 10 Tagen“ aus; der Tausch wird in den nächsten geplanten Stopp gelegt. Ergebnis: Deutliche Reduktion an Notfalleinsätzen.
Auf einen Blick – Predictive
-
Vorteile
-
Höchste Planbarkeit, minimale ungeplante Stillstände
-
Optimale Teile-/Personal-/Produktionsterminierung
-
Frühwarnzeiten (Tage/Wochen) statt reiner Schwellenwert-Events
-
-
Nachteile
-
Höhere Initialkosten (Datenintegration, Modelle, Change)
-
Bedarf an Datenqualität, Labeling, Governance
-
Erklärbarkeit/Vertrauen und Prozessanbindung als Stolpersteine
-
-
Geeignet für
-
A-Assets/Engpässe, hohe Stillstandskosten, gute Datenlage
-
-
Nicht geeignet für
-
Gering kritische Assets, fehlende Dateninfrastruktur, volatile Prozesse ohne stabilen Signalbezug
-
-
Daten & Tools
-
OT-Daten (Sensorik/PLC), Historian, Feature-Engineering, ML/Analytics-Plattform, CMMS-Integration
-
-
Typische Maßnahmen
-
Use-Case-Pilot, Datenaufbereitung/Labeling, Modellvalidierung, MLOps/Monitoring, SOPs für „Predictive Alerts“
-
-
Kennzahlen
-
Vermeidete Ausfälle, Frühwarnzeit (Median), Modell-Precision/Recall, Payback/ROI, Reduktion Notfalleinsätze
-
Tipp zur Integration aller vier Strategien
-
Denke in Asset-Klassen: C-Assets korrektiv, B-Assets präventiv/opportunistisch, A-Assets präventiv + CBM/PdM.
-
Jährlich RCM-/FMEA-Review: Ausfallmuster ändern sich mit Alter, Prozess, Produktmix.
-
KPI-Loop: Erkenntnisse aus Störungen zurück in Pläne/Grenzwerte — so wird die Strategie über Zeit präziser und günstiger.
| Kriterium | Korrektiv | Vorbeugend | Zustandsbasiert | Vorausschauend |
|---|---|---|---|---|
| Planbarkeit | sehr gering | mittel | mittel–hoch | hoch |
| Stillstandsrisiko | hoch | mittel | niedrig | sehr niedrig |
| CAPEX (Initial) | sehr niedrig | niedrig | mittel | hoch |
| OPEX (laufend) | unplanbar | planbar | effizient | effizient |
| Datenbedarf | keiner | gering | mittel | hoch |
| Eignung für kritische Assets | schlecht | ok | gut | sehr gut |
| Typische KPIs (Verbesserung) | – | MTBF↑, MTTR↓ | MTBF↑, OEE↑ | MTBF↑, OEE↑, Scrap↓ |
| Beispiele | Lampen, Kleinteile | Standardaggregate | Lager, Motoren | Engpasslinien |
Häufige Fehler – und wie Du sie vermeidest
Auch wenn Du die richtige Strategie auswählst, gibt es typische Stolperfallen, die Deine Instandhaltung im Alltag ausbremsen können. Hier sind die häufigsten Fehler – und wie Du sie vermeidest:
1. Predictive ohne Basis
Viele Unternehmen wollen direkt mit Predictive Maintenance starten. Ohne saubere Stammdaten, klare Fehlercodes und ein funktionierendes System für Wartungsplanung ist das aber zum Scheitern verurteilt.
👉 So vermeidest Du den Fehler: Sorge zuerst für saubere Stammdaten, standardisierte Pläne und ein CMMS, bevor Du Predictive-Piloten aufsetzt.
2. Overmaintenance
Vielleicht kennst Du das: Wartungsintervalle werden sicherheitshalber zu kurz gesetzt. Das klingt gut, bindet aber Personal und verschwendet Ressourcen.
👉 So vermeidest Du den Fehler: Analysiere Deine Ausfallhistorie und kombiniere präventive Intervalle mit zustandsbasierten Checks. So reduzierst Du unnötige Wartungen.
3. Alarmflut
Wenn Sensoren unzählige Alarme schicken, stumpfen Teams ab – echte Warnungen gehen im Rauschen unter.
👉 So vermeidest Du den Fehler: Lege Alarme gestuft an (Info / Warning / Critical) und überprüfe regelmäßig, ob Deine Grenzwerte wirklich sinnvoll eingestellt sind.
4. Kein Ersatzteilkonzept
Du kennst das Problem: Die Maschine steht – und das Ersatzteil ist nicht auf Lager. Das kostet Nerven, Zeit und Geld.
👉 So vermeidest Du den Fehler: Erstelle eine ABC-/XYZ-Analyse, sichere kritische Teile über Mindestbestände oder Konsignationslager ab und pflege Lieferzeiten im CMMS.
5. Silos zwischen Produktion & Instandhaltung
Wenn Produktion nur auf Stückzahlen und Instandhaltung nur auf Kosten schaut, arbeitet ihr schnell gegeneinander.
👉 So vermeidest Du den Fehler: Arbeitet mit gemeinsamen KPIs wie OEE oder First-Time-Fix-Rate und schafft Transparenz über ein gemeinsames Dashboard.
Dein nächster Schritt mit SIMPL
Mit der passenden Strategie allein ist es nicht getan – entscheidend ist, dass Du sie auch strukturiert umsetzt. Genau hier kommt SIMPL ins Spiel:
-
Plane und dokumentiere alle Wartungsmaßnahmen zentral
-
Erstelle mobile Checklisten und greife per QR-Code direkt auf Anlageninfos zu
-
Überwache MTBF, MTTR und OEE-Verfügbarkeit in klaren Dashboards
-
Binde Sensorik an und nutze Predictive-Ansätze, sobald die Basis steht
👉 So vermeidest Du die typischen Fehler und machst Deine Instandhaltung digital, effizient und zukunftssicher.
➡️ Fordere jetzt Deine Demo an und entdecke, wie simpl Dich unterstützt.